Accelerat.ai: Advancing Synthetic Data Generation for AI in Under-Resourced Languages
With its limitless potential to drive future growth, competitiveness, and job creation, AI, powered by synthetic data generation, is predicted to become the competitive advantage of the 21st century. As a result, AI innovation and adoption have emerged as key to international competition in both economic and state applications.
Europe remains behind in the AI race
According to AI Watch Index, Europe continues to lag behind the US and China in global AI power, despite recent healthy investment growth. While the US has a comparative advantage in several AI areas, such as AI services, audio and natural language processing, robotics, and connected and automated vehicles, one factor giving China its competitive edge is its access to big data, the fuel of AI development.
While Conversational AI is becoming mainstream in the US market, that’s not the case outside the US, primarily due to the scarcity of conversational AI data and the talent to build it. Millions of digital users are therefore forced to use English to interact with any AI-powered technology, ranging from social media to household appliances, because the cost to make these technologies accessible in the speaker’s native language is too high.
An AI Hub
Although the Portuguese language is the sixth most spoken language in the world, it is a low-resourced language from a digital perspective, especially when compared with English. In cases like this, a smarter and more efficient approach is necessary to speed up the development of languages in markets beyond the top 15 according to the GDP ranking of countries.
Daniela Braga, Defined.ai founder and CEO, stated in 2022 in a keynote address at Web Summit that Europe needs to step up its efforts to halt losing ground in the AI and digital space. She added that Portugal could be a driver of this effort, given the flourishing startup ecosystem and the claims that “the new California dream is in Portugal”, as well as the Portuguese government support of around 100M Euro in AI-approved new projects in the first year of execution of the Resilience and Recovery Plan launched as a response to the pandemic crisis of 2020.
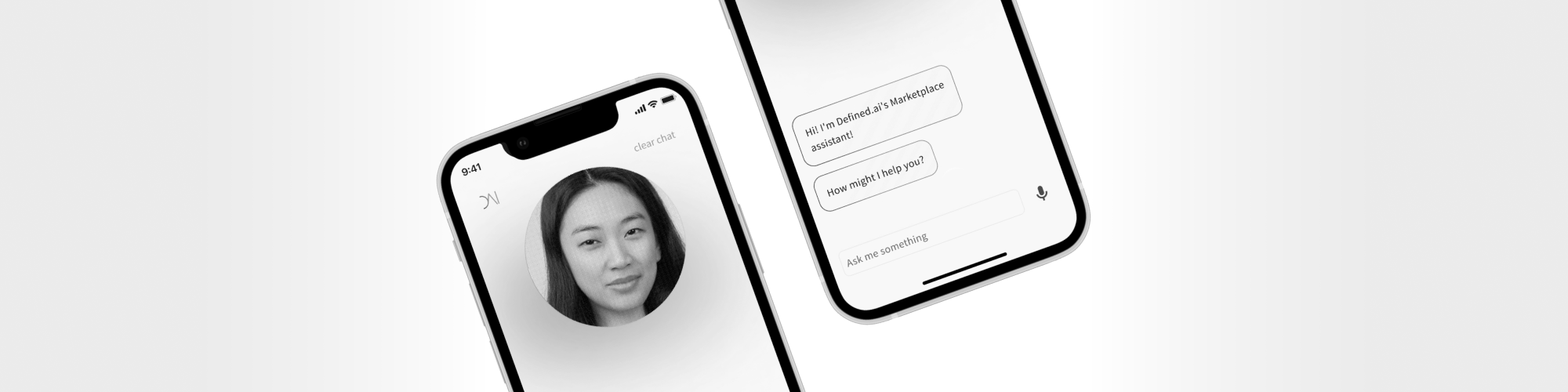
One of this AI projects is Accelerat.ai, a project aimed at developing solutions for digitally under-resourced languages and reinforcing European competitiveness in AI. Starting with European Portuguese, Accelerat.ai’s goal is to develop a modular conversational assistant that caters to language users outside the top-15 language roadmaps of the big 5 tech companies for the public and private sectors in Portugal and related markets.
Conversational AI is a powerful tool in automation of customer support in B2B businesses. It is estimated that 80% of customer calls and messages are about the same ten issues and that customer authentication takes up 25% of the time spent on-call with the customer. Top of the line virtual agents through voice or text interfaces can streamline these issues to take virtually no time at all, and it is Accelerat.ai’s goal to bring this technology to the diverse European market and to other geographies.
Technologies and State of the Art
The main goal of Accelerat.ai’s project research is to determine how best to build a model that can be trained like the commercial options already available in English but with less data. Currently, much of the AI industry is moving from big to small data and from real customer data (also called “live data”) to synthetic data.
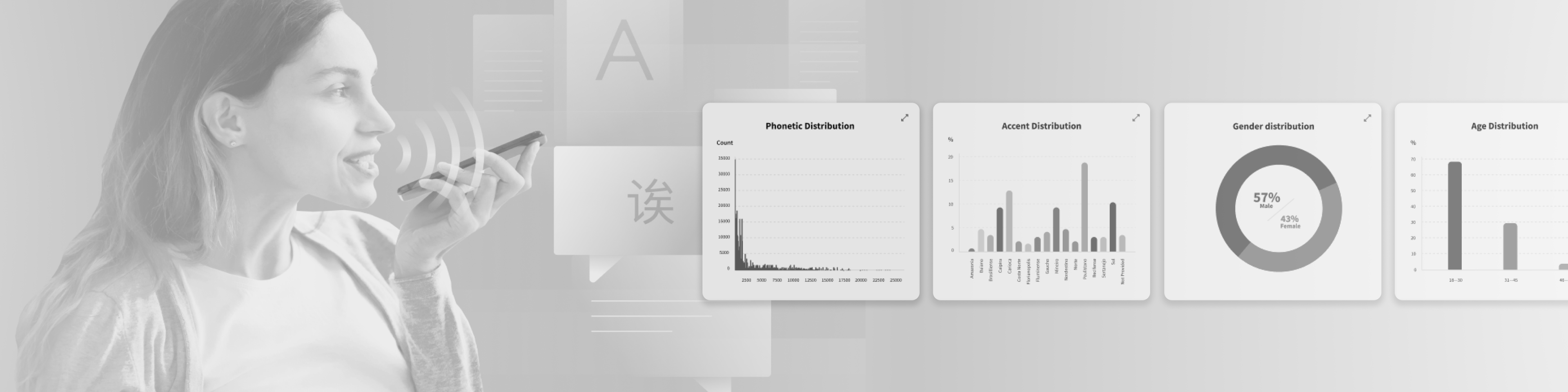
During the first stages, the focus will be on optimizing data so that the results are similar to those of the best automatic speech recognition (ASR) models. Most commercially available speech recognition systems in American English were trained with thousands of hours of real customer conversation data long before the advent of the EU’s General Data Protection Regulation and the requirement of an opt-out feature. The GDPR thus stopped these large tech companies with lots of resources from getting free data from users. Open AI ASR system, Whisper, was trained with 680,000 hours of multilingual audio scraped from the web.
Accelerat.ai’will thus focus on using smaller and smarter data (like synthetic data) applied to specific domains, to train future models. For example, synthetic voices can be used to build ASR models, and OpenAI’s ChatGPT can be used to automatically generate text for natural language understanding (NLU) models. The same approach can be used to build text-to-speech (TTS).
The above demonstrates the evolution of conversational AI technology from needing 50 hours of professional voice talent in a studio to 5 – 10 hours of smartphone recordings. Open AI just launched VALL-E, which after being trained with 7,000 speakers and 60,000 hours of audio, can generate a new TTS voice from only 3 seconds recording of a new voice. Accelerat.ai’s goal is to pioneer methods to train models on less than an hour of data and still garner an ambitious mean opinion score (MOS) of 3.5.
Finally, we want to build this technology modularly and agnostic from the cloud, making it flexible and easy to use.
Powered by Defined.ai
Over its brief history, Defined.ai has built a platform for AI data collection, processing, enrichment, and transformation, delivering resources and expertise to businesses to accelerate the building of myriad AI models.