
The Pros and Cons of In-House Speech Recognition
Speech communication plays an essential role in how we communicate. Thus, it is only natural that we seek this form of natural interaction with machines as well. Automatic Speech recognition (ASR) or Speech-to-text (STT) has been a field of research for many decades. Performance of these systems has progressively improved over the years. Although many sensationalist articles claim that ASR is solved, many challenges remain, such as ASR robustness to age and accent variations, conversational speech, analysis of paralinguistic events, spoken language generation, noisy real-life scenarios, etc.
The ASR market is evaluated to be USD 4.1 billion by 2024 (MarketsandMarkets Research Private Ltd.), being applicable to any business that encompasses or is appropriate for speech-based human-computer interactions. Hence, we see telecommunication, insurance, finance and retail companies, which are from distinct business-verticals taking their shares in the application of speech technologies. It is our belief that the industry has only recently started to uncover the veil around speech technology, exposing the fact that the range of applications is much wider than what is explored today. It raises the question as to whether that market value is much higher, since a great deal of revenue is indirectly generated by speech technologies, which have turned many core services more accessible.
Although it sounds appealing, developing a well-conceived production-ready speech recognition system is a cumbersome task and requires significant investment. This high initial investment is often a barrier in developing a proprietary system. As such, companies opt to use automatic speech recognition (ASR) services provided by existing players in the market such as Amazon, Microsoft, Google and Nuance, to name a few.
There are also smaller companies or start-ups emerging in specific areas of spoken language processing (e.g. SoundHound, Speechly, etc.). However, many times, these start-ups focus on specific domains, use cases and/or specific languages, and often end up being acquired by larger companies. Especially when they have developed a breakthrough in terms of technology (e.g. Vocalize.ai, Tellme, etc.).
In this article we analyse existing services, the technological framework behind them and with the pros and cons of developing your own ASR.
During the 90s and the early 2000s, speech recognition was sold as a software package that you would install on your computer. This was the first breakthrough in speech recognition technology, where Large Vocabulary Continuous Speech Recognition (LVCSR) was made possible and many systems could achieve around a 30% WER (Word Error Rate) in a controlled setting (Wang, et al., 2003; Hinton et al., 2012).
In the last 8 years, with the rise of cloud services and GPU computing, we have seen a growing adoption of speech to text services hosted on the cloud. The cloud has broken hardware barriers, accelerating adoption rates. You no longer need to install software on your computer or embed the recogniser into your device (provided you have a stable internet connection). These services rely on a business model where you pay for audio processed, with discounts when this amount exceeds pre-defined thresholds. Another factor is recognition accuracy. Depending on the task, WER rates are now as low as 5-15% (Hinton et.al, 2012; Chiu et al. 2017).
These lower rates are seen in systems trained with more than 10k hours of voice search data (ex. Google Search, Bing, etc.). In the case of more spontaneous speech, e.g. YouTube video transcriptions, WER rates are around 40% (Liao, et al. 2013). It is important to note that these studies are academic in nature, so real-world examples can be different. Telephone conversations vary greatly in audio quality, can be noisy or even present interruptions and speech disfluencies. When these characteristics are present, they can be confusing to the model, reducing recognition accuracy even further.
The accuracy of these services varies according to the domain (e.g. retail, finance), languages and variants (e.g. pt-PT v pt-BR, en-US v en-UK) and environments (e.g. in-car, landline telephony, mobile). Some providers also have the capacity to do automatic punctuation, detect languages and predict speakers in conversations (diarization).
Speech to Text Service
Several studies show that a generic model will have worse performance than a model tailored to a specific recognition use case (Susuki et al., 2016). Accuracy gains from model adaptation depend on many variables (channel, speaker, topic, etc.). Hence, we saw a first wave of completely generic industry services that would have WERs below 10% with native speakers in quiet environments but where WER would jump by 40% when applied to real-world scenarios such as call centre communications. In the past years we observed increased investment in less generic models or even in frameworks where one can adapt acoustic and language models to specific business verticals, using proprietary data. The challenge for the industry is to find the trade-off between market size and a more targeted model, i.e. the more niche the offer is, the smaller the market.
Interactions with these services are made via either synchronous or asynchronous methods:
- \\ Synchronous
- Used as a command and control modality, where speech is processed in a synchronous way and we receive a response with the recognition result.
- \\ Asynchronous
- A stream of speech processed asynchronously enabling scenarios such as real-time recognition.
Technological Framework
Frameworks and toolkits like Kaldi were initially promoted by the research community, but nowadays used by both researchers and industry professionals, lower the entry barrier in the development of automatic speech recognition systems. However, state-of-the-art techniques require large speech datasets to achieve a usable system.
The analogue audio signal is converted into a raw digital waveform using classic audio processing toolkits, features are extracted by a variety of algorithms, in the case of Kaldi these are usually some of the classic signal processing features MFCCs (mel frequency cepstral coefficients), Ivectors, Pitch and energy coefficients. The complex part is the decoder, because all three models must be sufficiently trained with good data.
A typical ASR pipeline is made up of three parts, as depicted below:
- \\ the input waveform;
- \\ feature extraction;
- \\ and the decoder, which in turn is made up of three parts:
- the acoustic model;
- pronunciation model;
- and language model.
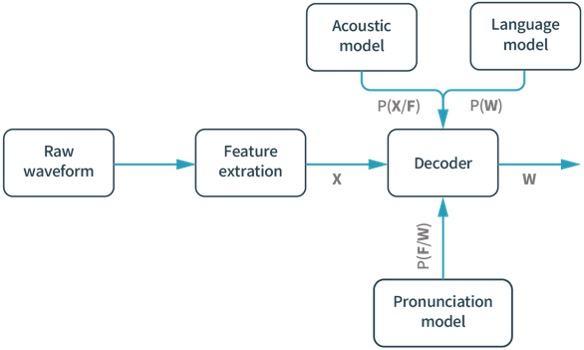
Decoder Decomposition
Acoustic Model
- \\ Model which bridges small frame-based audio segments with phonemic- (speech sounds) based features;
- \\ Data required – Annotated Speech Data:
- The model must learn which speech features go with which types of sound combinations over the spectrum. Also, it must not learn (or create bias) towards sample noise or specific artifacts, i.e. the model must generalise well for the target speech. Well-balanced data can give better coverage and make the model less complex.
Language Model
- \\ Model which bridges small frame-based audio segments with phonemic- (speech sounds) based features;
- \\ Model of phrases in the language or a model of grammar:
- Highly domain dependent. This is because the types of phrases uttered by someone when writing an encyclopaedic entry (e.g. Wikipedia) is different from a news column or a conversation between friends which in turn could differ from a pizza order;
- The goal is to navigate the “noisy channel”, which is the task on selecting the best output sentence based on the probability of that phrase being uttered by the speaker given the posterior probabilities (or confidence) of possible candidates produced by the acoustic and pronunciation models over the entire phrase.
- \\ Data required:
- A balanced corpus (or dataset) of sentences which are representative of the phrases which could be uttered by the user in the application;
- Important that out-of-domain phrases do not create confusion;
- Can be broken up into multiple models (or grammars).
To develop a state-of-the-art ASR system, you will also need the following resources, also called prerequisites:
Tokeniser
- \\ Handles raw text data, which when collected can contain unwanted symbols and non-printable characters (which create noise);
- \\ Separates tokens by considering non-printable characters and spaces (line breaks, tabs, control characters, etc.) as well as logical semantic breaks, intended to facilitate pre-processing in the subsequent modules (symbols or punctuation). Since this is the first module, it is important that issues do not propagate;
- \\ Disambiguates abbreviations from sentence terminators.
Text Normaliser and Inverse Text Normaliser
- \\ Text should be normalised which contains non-pronounceable characters like digits and symbols where the decision about what should be spoken is not trivial (Cardinal numbers, Ordinal numbers, Dates, Telephone numbers, Money, Times, Measurements, etc.):
- Example: should “1/12” be pronounced as day/month, month/day, month/year, a page number, a fraction, etc. So, the context is important.
- \\ Inverse text normalization is the opposite operation where ASR output is inversely normalised:
- Example: “one hundred and fifty-three dollars and eighty-seven cents” should be represented as “$153.87”.
Grapheme to Phoneme (G2P)
- \\ Normalised text must be accompanied by the full phonetic transcriptions which correspond to the training audio in order to create the proper training alignments for the acoustic model;
- \\ Used to create the pronunciation model, as explained above, to decode new speech.
For top tier languages like US English pre-requisites are easier to create because decent phonetic dictionaries, tokenizers, and some simple normalization operations are included in opensource libraries. Unfortunately, even these resources are far from the State of the Art. For smaller markets and countries with a less active speech research community these pre-requisites are harder to find and often must be built entirely from scratch.
Recently, end-to-end models have started to gain the relevance in interest of the research community (Graves et al., 2014; Amodei et al., 2015; Rao et al., 2017; and Tüske et al., 2019). The end-to-end model directly maps the input audio to the respective text output. These models jointly learn the several parts of a classic ASR system, skipping the effort of training separately an acoustic model, a language model and a pronunciation model, and reducing training time as well as decoding time. In some approaches, researchers aim to learn the traditional features (which typically require great effort from engineers and linguists) directly from the data. This saves resources and time. A recent overview of end-to-end models can be found in Wang et al. (2019).
End to end models are generally built in one of two ways. The first is by using sub word units as in Xiao et al. (2018). In this approach, linguistic knowledge is still necessary to build useful morphemes (parts of words like the root, stem, prefixes, suffixes, past participles, plurality or gender markers, conjugation, etc.). Graves et al 2014, highlights why phonemic information is still important, but in the case where out-of-vocabulary words are common, end-to-end approaches provide an interesting alternative and remains an open research topic.
The second approach is to directly abstract speech information from the signal as in Collobert et al. (2016) and Hannun, et al. (2014), usually by way of vector embeddings. Some studies use signal pre-processing by way of Discrete Fourier Transforms (DFT) to generate a spectrogram which is processed as an image and features are extracted in raw-form for the acoustic model (Shulby et al., 2019). Also, word embedding-based language models (Bengio & Heingold, 2014) can be an alternative to handcrafted language models and often can be leveraged in multi-lingual scenarios. Still, one needs an extremely large corpus to abstract this information well (many terabits of text from target language usage).
In House Development
Companies like Amazon and Google group languages into tiers according to market size. For example, tier 1 languages are often US English, Spanish, German, French and Chinese because they represent a large number of consumers. Research in ASR for under-resourced languages is an on-going research topic (Besacier, et al., 2014) and most works focus on top-tier languages. For languages like Portuguese (de Lima & Costa-Abreu, 2019), there are very few resources available and other studies have shown that for languages other than English, some domains can differ greatly in accuracy depending on the domain when generic models are used (Iancu, 2019).
Customization is especially important for domain-based applications, like dialogue systems, whose input contains specialised vocabulary (Morbini et al., 2013). Out of the box systems like Google, Amazon or Apple do not allow the user to specify or provide custom language or acoustic models, only the result is provided. Moreover, those results are subject to change depending on differences in versions as those companies develop their models. Not only the accuracy of the models can change but also the way in which the result is presented, resulting at times in unpredictable inverse text normalization results which could propagate errors in an application which was expecting a different input.
Building your own speech recognition pipeline has the following pros and cons:
Pros
- \\ Adapted models:
- often companies are sitting on significant amounts of speech data from call centres and customer interaction; after processing, this data can be leveraged to improve and adapt existing models. Adapted models will have improved accuracy rates be tailored for a business contemplating specific jargon or brands.
- \\ Costs over time:
- cloud based speech services are often charged based on audio length; most plans charge for each time the API is called, meaning that a company would have a high recurring cost for usage which would increase with wider adoption of the service.
- \\ Data privacy:
- having your own ASR avoids you from sending client data, which may contain sensitive and personal information, to a 3rd party
- \\ Service dependency:
- remove a 3rd party dependency and give the capacity to establish a predictable and dedicated roadmap.
- \\ Service resell:
- opportunity to address a specialised market.
Cons
- \\ Long-term investment:
- there is a significant initial investment in software infrastructures and resources.
- \\ Expertise required:
- you need to find a team with roles such as computational linguists, speech engineers, DevOps engineers and back-end software engineers.
- \\ Data required:
- capacity to collect and process large datasets necessary for a successful product.
Financial Considerations
The make or buy decision also contains a financial component. One needs to weigh up the OPEX costs for an API call to one of the cloud-based ASR systems, versus investing in a generic or domain specific acoustic and language model.
Let us assume the following scenario: 35% of the Portuguese population has access to voice activated services, which represents approximately 4 million people. Each voice interaction, typically lasting 15 seconds on average, would be charged EUR 0,005 per API call. If somebody uses the service 5 – 10 times/month, the total spent on API calls ranges EUR 1,200,000 – 2,400,000 per annum.
This number exceeds the total development cost by a considerable margin. Considering the advantages of a bespoke and well-tuned version speech recognition engine, which carries a total development cost between EUR 1 – 2 Million (can be higher or lower depending on the company speech tech maturity), as opposed to a ‘one size fits all’ variant the choice is easily made.
Conclusion
Developing an ASR system that performs such that users enjoy the interaction, require considerable development work and investment. Much of the work is related to collecting and processing many hours of recorded speech that are relevant to the domain or domains in which the system will operate. Obviously, the language is a key component in the quality of the recogniser, including regional variations, dialects and accents.
The publicly available recognisers typically provide good, but not great performance. They are generic solutions that do not necessarily match the requirements of specific verticals or industries. Certainly, these recogniser s work fine for many, but if you need top notch performance to ensure customer satisfaction and enhance your brand, you should consider a domain specific solution.
In the case where a recogniser is meant to be used in “on-the-job” situations, like utilities repairs or house calls, it is likely that generic models will not meet expectations for application developers due to background noise and distance from the device. Similarly, if the recogniser is meant to be one of the first steps in a larger application (like a personal assistant), a custom solution offers more predictability, liberty for developers and higher accuracy. Also, if you are in the business of offering speech recognition and language understanding services as part of your business model, the pay-per-use model deployed by the cloud-based tech giants may be too expensive in the long run.
The business case for a customised, highly performant engine as opposed to a generic, one size fits all solution is justified when you take the factors stated earlier in this article into account. The more specific your domain, the better the recognition accuracy you desire, or the higher volume of traffic you generate, are all parameters that point in favour of creating a customised solution.
That is particularly true for systems deployed for smaller languages, with fewer speakers and less economic prowess.
Bibliography
Amodei, D., Ananthanarayanan, S., Anubhai, R., Bai, J., Battenberg, E., Case, C., … Chen, J. (2016). Deep speech 2: End-to-end speech recognition in English and Mandarin. In International Conference on Machine Learning, 173–182.
Besacier, L., Barnard, E., Karpov, A., & Schultz, T. (2014). Automatic speech recognition for under-resourced languages: A survey. Speech Communication, 56, 85–100. doi: 10.1016/j.specom.2013.07.008
Bengio, S., & Heigold, G. (2014). Word Embeddings for Speech Recognition. In Fifteenth Annual Conference of the International Speech Communication Association.
Chiu, C.-C., Sainath, T. N., Wu, Y., Prabhavalkar, R., Nguyen, P., Chen, Z., … Bacchiani, M. (2018). State-of-the-Art Speech Recognition with Sequence-to-Sequence Models. 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 4774–4778. doi: 10.1109/icassp.2018.8462105
Collobert, R., Puhrsch, C., & Synnaeve, G. (2016). Wav2letter: an end-to-end convnet-based speech recognition system. arXiv preprint arXiv:1609.03193.
Graves, A., & Jaitly, N. (2014). Towards end-to-end speech recognition with recurrent neural networks. In International Conference on Machine Learning, 1764–1772.
Hinton, G., Deng, L., Yu, D., Dahl, G., Mohamed, A.-R., Jaitly, N., … Kingsbury, B. (2012). Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Processing Magazine, 29(6), 82–97. doi: 10.1109/msp.2012.2205597
Hannun, A., Case, C., Casper, J., Catanzaro, B., Diamos, G., Elsen, E., … & Ng, A. Y. (2014). Deep speech: Scaling up end-to-end speech recognition. arXiv preprint arXiv:1412.5567.
Iancu, B. (2019). Evaluating Google Speech-to-Text APIs Performance for Romanian e-Learning Resources. Informatica Economica, 23(1/2019), 17–25. doi: 10.12948/issn14531305/23.1.2019.02
Liao, H., Mcdermott, E., & Senior, A. (2013). Large scale deep neural network acoustic modeling with semi-supervised training data for YouTube video transcription. 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, 368–373. doi: 10.1109/asru.2013.6707758
Lima, T. A. D., & Costa-Abreu, M. D. (2020). A survey on automatic speech recognition systems for Portuguese language and its variations. Computer Speech & Language, 62, 101055. doi: 10.1016/j.csl.2019.101055
Morbini, F., Audhkhasi, K., Sagae, K., Artstein, R., Can, D., Georgiou, P., … Traum, D. (2013). Which ASR should I choose for my dialogue system? In Proceedings of the SIGDIAL 2013 Conference, 394–403.
Rao, K., Sak, H., & Prabhavalkar, R. (2017). Exploring architectures, data and units for streaming end-to-end speech recognition with RNN-transducer. 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 193–199. doi: 10.1109/asru.2017.8268935
Shulby, C. D., Ferreira, M. D., de Mello, R. F., & Aluisio, S. M. (2019). Theoretical learning guarantees applied to acoustic modeling. Journal of the Brazilian Computer Society, 25(1), 1. doi: 10.1186/s13173-018-0081-3
Tüske, Z., Audhkhasi, K., & Saon, G. (2019). Advancing Sequence-to-Sequence Based Speech Recognition. Interspeech 2019, 3780–3784. doi: 10.21437/interspeech.2019-3018
Wang, D., Wang, X., & Lv, S. (2019). An Overview of End-to-End Automatic Speech Recognition. Symmetry, 11(8), 1018. doi: 10.3390/sym11081018
Wang, Z., Schultz, T., & Waibel, A. (2003). Comparison of acoustic model adaptation techniques on non-native speech. 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP 03)., 1–1. doi: 10.1109/icassp.2003.1198837
Xiao, Z., Ou, Z., Chu, W., & Lin, H. (2018, November). Hybrid CTC-attention based end-to-end speech recognition using subword units. In 2018 11th International Symposium on Chinese Spoken Language Processing (ISCSLP) (pp. 146-150). IEEE.